class: center, middle, title-slide .title[ # Aula 7 - Obtendo dados <br> Raspagem ] .subtitle[ ## Jornalismo de Dados ] .author[ ### Leonardo Mancini ] .date[ ### 2025 ] --- # Obtendo dados Podemos obter dados: .pull-left[ ** Manualmente ** - Disponibilizados por órgãos públicos, ONGs, institutos de pesquisas, etc. - LAI (Lei de Acesso à Informação) Dica: [Agregadores de bases de dados](#agregadores) ] .pull-right[ ** Coleta automatizada ** - APIs (Application Programming Interface) - Raspagem de dados ] --- name: agregadores # Agregadores de bases de dados Além da busca e da LAI, há sites que agregam bases de dados tabuladas de diversas fontes. - [Google Data Search](https://datasetsearch.research.google.com/) - [Harvard Dataverse](https://dataverse.harvard.edu/) - [Kaggle](https://www.kaggle.com/) - [Brasil.io](https://brasil.io/home/) - [Base dos dados](https://basedosdados.org/) - [Ipea](https://www.ipea.gov.br/portal/) Para ler artigos acadêmicos: [Google Scholar](scholar.google.com) --- # API API (Application Programming Interface) é a maneira como aplicativos conversam entre si. Uma API pode trocar dados entre aplicativos, de forma organizada e estruturada. .center[ 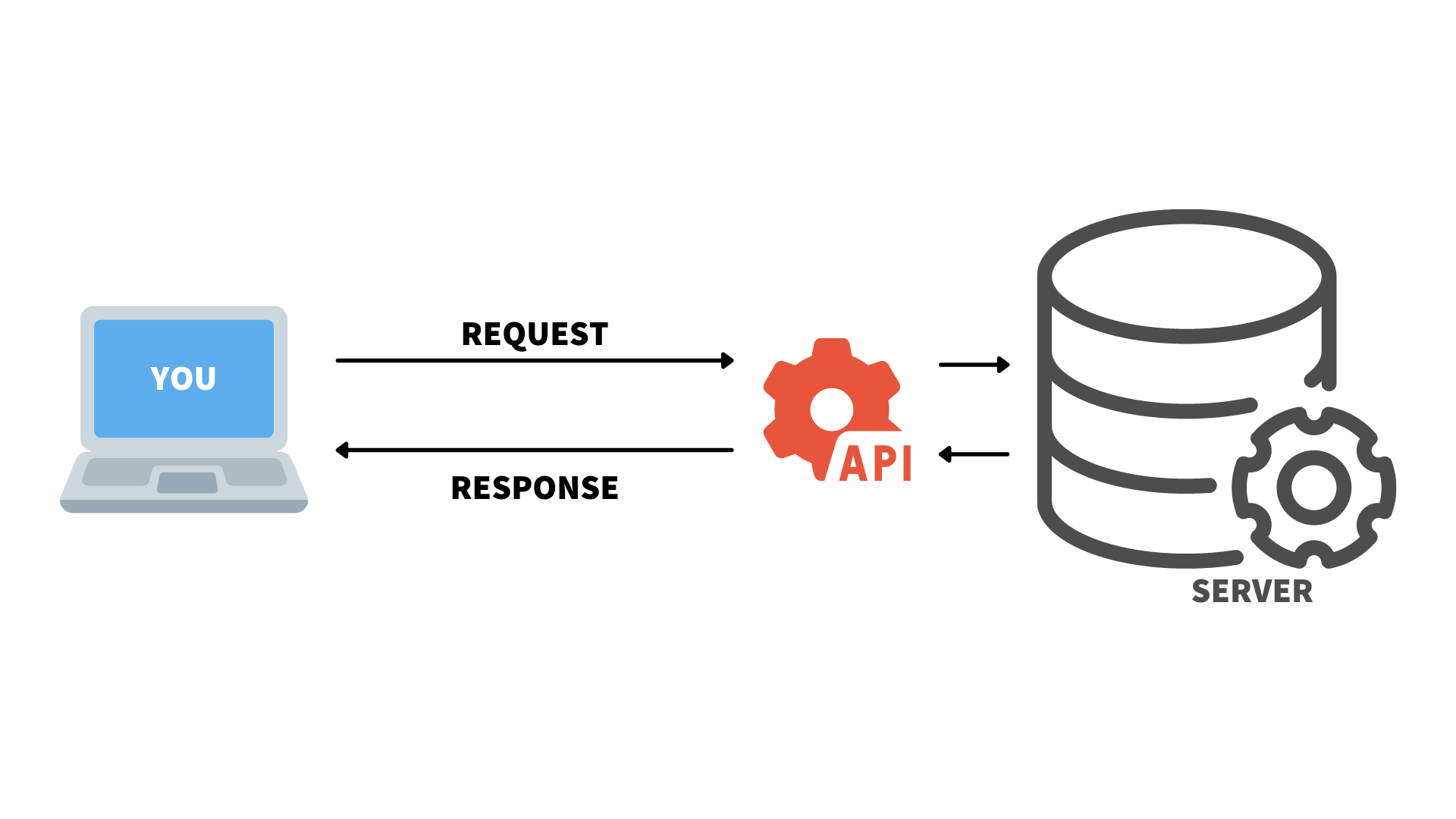 ] --- class: inverse, middle, center # Exemplo: _Geocoding_ ??? Pegar o exemplo de geocoding "exemplo API e raspagem.R" para montar um mapa com os endereços dos estudantes --- # Raspagem de dados Raspagem de dados é a técnica de extrair informações de sites de forma automatizada. É a parte mais complexa e "artesanal" da extração, já que cada site é único e pode adotar soluções e estruturas de código diferentes. Há algumas ferramentas que facilitam a raspagem, mas, se o site for realmente complexo, é necessário programar um script específico. --- class: inverse, center, middle # Relembrando HTML --- # Tags (ou, etiquetas) Tags definem a característica de determinado conteúdo. Um elemento HTML é composto de uma _tag_ de abertura, o conteúdo, e uma _tag_ de fechamento. <br> .center[ <img src="./imagens/html_tags.png" width="450px" /> ] --- # Tabelas .center[ 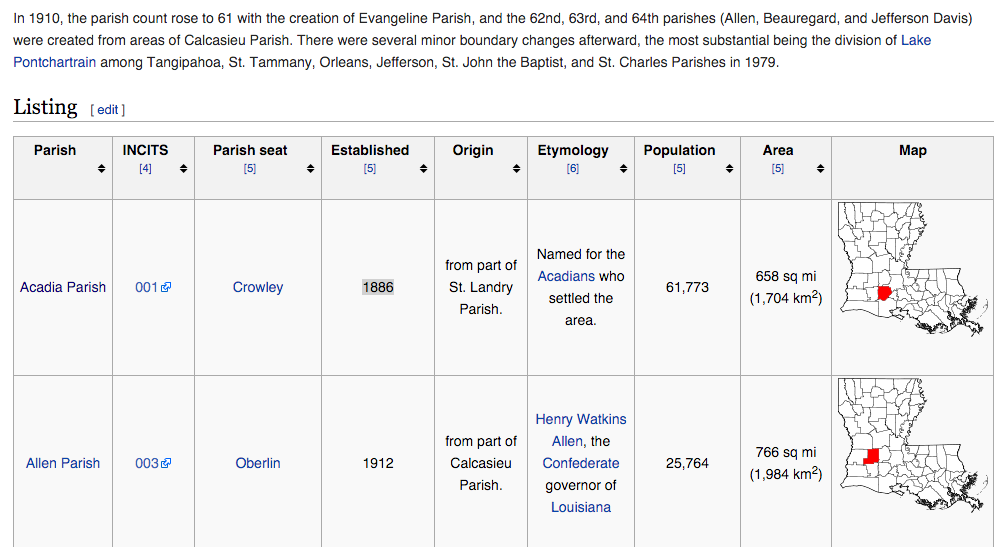 ] --- # Tabelas .center[ 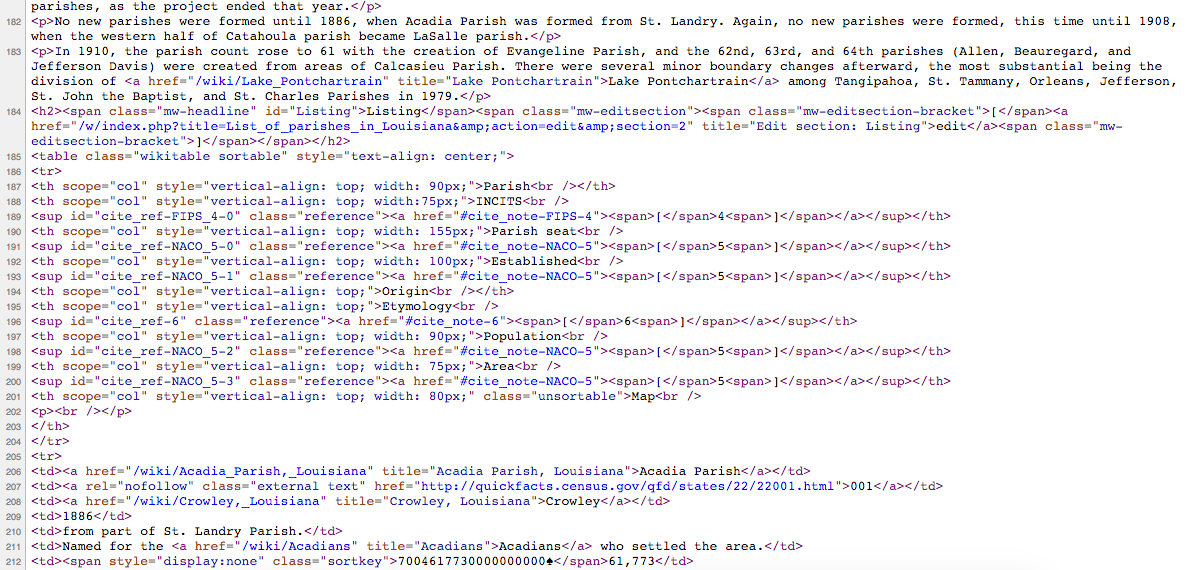 ] --- # Tabelas As _tags_ relacionadas a tabelas: - `<table>`: indica o início de uma tabela - `<th>`: célula de cabeçalho (table header) - `<tr>` : linha (table row), - `<td>`: dado dentro da célula (table data) .center[  ] --- class: inverse, middle, center # Raspando com o Google Sheets --- # Raspando com Google Sheets Considerem os dados da Wikipedia sobre os <a href="https://pt.wikipedia.org/wiki/Lista_de_vereadores_da_cidade_do_Rio_de_Janeiro_(2021-2024)"> vereadores do Rio de Janeiro </a> .center[ 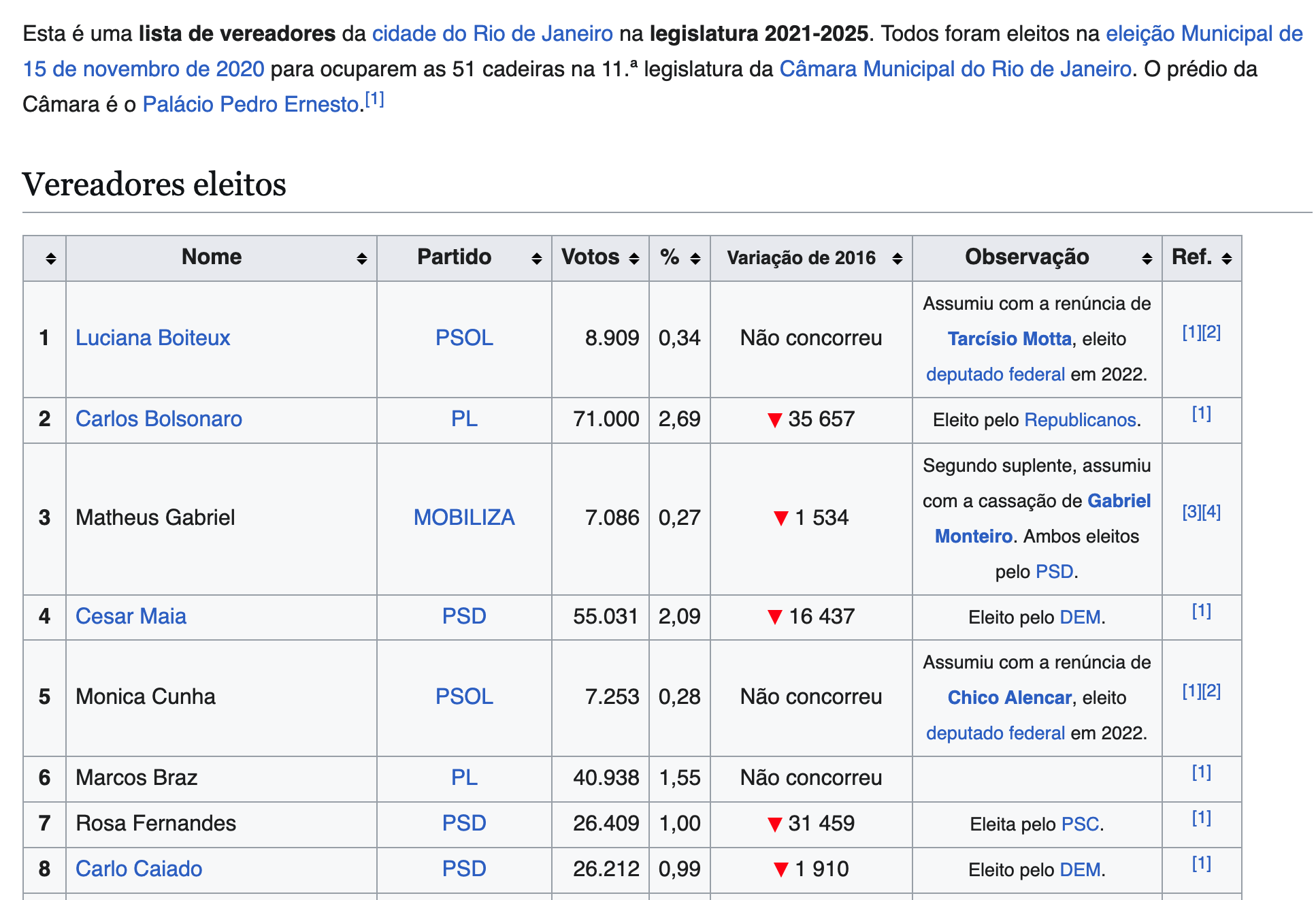 ] --- # Raspando com Google Sheets Para extrair os dados, usem a fórmula: ``` =IMPORTHTML("url", "element", 1) ``` Sendo: - A **url** é o endereço da página que contém a tabela.<br> - O **element** é o tipo de elemento que queremos extrair. No caso de tabelas, usamos **table**.<br> - O **1** é a posição da tabela na página. Se houver mais de uma tabela, podemos mudar o número para 2, 3, etc. --- # Extraindo com Google Sheets A função `IMPORTHTML` aceita, além do elemento "table", o elemento "list". ``` r <ul> <li> Esta é uma lista não ordenada</li> </ul> ``` ``` r <ol> <li> Esta é uma lista ordenada</li> </ol> ``` Neste caso, a função `IMPORTHTML` ficaria assim: ``` r =IMPORTHTML("url", "list", 1) ``` --- # Extraindo com Google Sheets <small> .pull-left[ É possível extrair dados usando feeds RSS, que são arquivos XML que contêm informações sobre as últimas notícias ou atualizações de um site. ] .pull-right[ <img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAOEAAADhCAMAAAAJbSJIAAAAh1BMVEX/////kTP/jCT/y6b/kDD/ix//jy3/jir/ihz/iRf/iyL//vz/+fP/kCz/jif/8OX/p2L/3MP/0bD/9ez/487/7N7/lj3/1rn/q2r/07P/o1n/xZv/rnH/tX3/v5D/6Nf/nk//sXb/m0j/lTr/uYf/yKD/wpX/hQD/2sD/m03/pV7/6Nr/uYaw1XhuAAALH0lEQVR4nO1d2WKiSBSVoopdUMB9x2g7dv7/+0aT7nTamDr3QiE4w3kP1qHuvpBer0OHDh06dOjQoUOHDh06dOjQoUOHDjUiy4eT1LbTNJ1Nhnk+yqIoDJs+lFEcfqggEFcEgfI831dyPJ+u1vbpZxI1fTgjsIV1Aykdx3WF8tzxdrqe5VnTR6yIrwz/4uoGSsjzcTJq+pzloWP4m6gTB348OJ6yp1RQAsN3OLES29Xs+S6TzPDtNt0gLnan57JALIbvLJVfHDbPI7Bshm8shT9+yZ/kKksxfLtKb7wbPsNNlmX4RlJZr3nTBCAqMHwj6e8XSdMc9KjG8EpSeINJm1WyMsMLHLVft9dPmmB4ucjYGwybpvINzDC8wPGLtJXCaozh5SLV+NjCRMQgw6vVcV5bx9Eowzf3sWqZ9zDM8AJXvbSKo3mGlhX31y2yOXUwvDiPeNGakLUWhleb0581Te0XamJ44ejN2xED1MbwGswt2+A6amR4MateC9SxVoaWFRSNJ5A1M7yo46phUa2b4cU7WpP/OENL+tMmr/EBDC8WRzboHA8/rg2nKzzPu7ahXMeR0jRFqZaNxXGjU75JsixJktHm2ko8vEznY+kKdaFqkqhrtcP//0KYbIb2alD0PeGaoin9dfO+8RZRkturrfCEY4RjsG1VVvWBMMrtqfADA5fp9Jv1G1qM0uU4qHyX0l81TUSHcLMYxMqtxlHM2ympH8hmu9irdJOu1XigihCepkFQgaT07KYpYESTcyzKGx5/1T638RXJofBLq6Q4t6hQ9T3CfOmXvUh33HJ78xvZwiqpkY5qvb35hXC2LWdapWqx87/B8OyX4SjVoemT05HPS3H01k0fnIF8oEpw9Fodwt0in3t8u6p2z+AYP3AqFJtiMG361DzYIuZSFIOnusVe9MLOr56NYu/nmauO4vxkFHuzmBmuikHTR+Yi2ineNYrps91ibzjmVZmDXdMnZiNa+axrVE/l+t8x5NVzniqA+4VoGrAoPlEY/gGbZXCeKJn6g82YEeLIp0mJPyNcMiJVqZ6ksPE3OJLqjGsqT4VRloxGP0ejJMki4643t+iBqltTiJpKy4mFiOO+tMbFP+fdOh1uzL3NpKAro6jHLdrBhyBJeV1Wu+7l+fF8PTO0FsNQRr+Wavg3fXzHDXwxX0+S6jTXdIpeHQZVN6nguEoUq0lVI5eS7Y20ajCoaBZDusotFptKvzEkJ43u3BCtT6BMm8jYt45V1HLTp5rUGqwNcZ7mQrJYlN8aGe2pFH3j4Rt9YkiKeDApe5EJlaLsm1ZF1kyUo/rrkgNc0Z6YTzlbw46fOfV1kdZdObOTbYkUA8PJIn+uzS254pQVRIq+2empMpN7jpqXcc0RURelZTQGLzeb6PhlOFIpusvmGV45Tvn6SLWoRjP+8vOlbvzKlqZRnxTdSGlw5LbKBG3cT7k/t6EFcK7BplSlGWHpbbmiOvRITzYY2lScgnY87tRoSkqmDNrTynPegrtRQcsXY2MhePVJdum/8n5ySSpsGMuGTczqiy0r6wgLis+QhaH41Mg2guOyKiwJaRnA1MCNoX18teS88SFJFT0zTtHURkk85kiqTaFoKHgz98WBmOPCSNbGTC/D3FaQ9I/0nw3HBFV0jNSlTO49KUa7ekORU89EZGN0s0vM6ZEIRRWlNOAxzO6uuQW9jjQlpPxi0TaGlrMnm9SIUAqXbvXw1Pbj60chhRCx6xrYy3NicrYx9PHj4uplqdPqaKezWWof1qvlYGspT7iVVkYY/eoVdhnGy6dhluT2yzz2K2zlyZhKMSK4jPjFLMPfREfprq/KLnLRKZ4I9lTVt0M8ss+yzHDzVVCpurjD9tRl5mY8JLNpqfUfGRMtakR4ul/zInhml1n/cfZEA5Hiso0Bc4qwWYqYe5FOQXRkZ6gHRkuL3yFbW1xhpXZzNzjiMBHYYEQLixn8CGIY/gqdoqxrlugG0ZGpj4qWTEX4zalHfZEhWvE8JDH3wUmGLGpm9gebAWcUX7o0n1HAZ/oPHFyc9Rmi6oxJ6d0JegznkfP80ZJxjTGtljSHwu89dDRzIunXSNvbzqEmPsDrf0Y2JU+qEVURuv1HOYwPLMjbBs6W8rwc5sIPnwMfkrPkgJTfQU10Hr7Hl2ypk7EkS0+4xIePgYdUZaT1kOAlPiY4/RsrWr/aEpToDTa/5b52Ql9xIN6iR8n4t+gS/WozruVg026RZE9TtEVUbzXj22MRKp7XSyQMpYSoVCutRtYUCUWI6+Ecgr8+IuPc0N4QqdVJKnpmSB7chrYUF6RbpNTepsDWPDxy+40VZdGQ0rCGXr+WbQwKppTohhDZhCgTdusp8GOE0JVZNI+xQKsfpiZs2EgoI5WESxyhvNNv7J9o4LiZNnWA0kRhbFs4yu3X89jq77fL44Tyr8gWlB4Snk+fAaNlqOYWTZbXj3o611096cbK2x5x4jLAhQ1CNSlCL8o34C+y9di7aY46QgyQEiWEr7kSWm7IJRLkACB8VXd7MI43B0o+wY7fxWV+1DGtHNac9t/aawd9QXaJ5RQ3ApGYVlTE8FVbCQVfkM1w4z/GqTB6T8Qq+n1EW+BwHUerjTMop7IPD4GsaZWSW4J3y6R30j1hAEMbfL4MRIAVFDGjbLNIT2fLcK+T4DCA05elV/eiMan+qR+yWEEpiKFnRbGpKNvxJnjsd4p7jc+NYPCGS4JoKFMrRRpQoq53aBO9I5JTLGThXm+SCfb4HkjTrL+ga+xGcPAPlwRBWFOyk4j7d3+gHWpFWkS4ghQ8Ii5DkBBxfYKuhB1ZqCQIK9cjoMx+mf4FZaj80yFjjbFZo4oGTmKBxpTx+ZQBwc8Qmr5ugsQUJ7FAEcuYGpSy3EJbckGBpdT98RvAWLZzZhNM2HN5OrcPCxou0qNcbxWkZDOELZEv0PptpNRKG9v28IxUzI5qCEOsN9B2nNHsP4ydw63+HbHbF6T1nBv0NdY0Q0ksDGtAeBtwjSlsiNyB1uQjwyWQIgIpcLmjNUCx70KrS0ivoUMDJ3K4O3sTtqHRe8RegroP6A4SfdRAm9D5BBQH3mWoddsgiYXF70jfoWE32crsPcXaNO+AzD0yNeAVcbdozDNEuRjMoIAx9X7yGPIdPtDDXg+0ogI00wxyMG7hm7ZWfXNG/WwFiE2hqQFHAu/3C1A+dg+g3QyMF4ydN3qx4jrEiP0tfFie34CXhtJ04C7YNVNOCeMdqNscgpeGemRgeIg9iAnT8i+ALxG8NDjnpq+3OXNmVRgPWd8CLni86E0NNIb67ELSNgD+gJ1c4E0r4GMFGnPTB+/8j/NwxRRP/4DYGRrDVyADXIYJU0xxCgqeCJvBIO7jr1zysnxCbJ/py6bQIQKHyh+rSVhOn/BVQ1CIkP+AvwcZXYn5tgUjNiV9NEbfLIXTWyBsK8GQ9uGm99PBauAV+sgUZnjAUpWZOaE3nzzSsqM+/5EWMBWIYZlmPnFg2wpoMSFwQBLIwUbPEKZfd3GkjfoSS+rA3KMsHeQ7MGK4jxcCRXdL9LUgqEEz0cC4l2TYW+MuPPkLQsChVWVY9vP7qf4/bkrGP/MDgz8CMARV6tIMe5tCczCX81m9tjLshYvvVu6lP+XU8OqVUlAmAs/e3Ru/dFXBc7Koy1nRW1TbJ02OhYo/KaR0VX/KDSL0Gz6VPX7VOdowP55jX10/jqU8r9jN+NMPK19oEEhgk08/dH8ufpjYLIlGw9S200lOmWO/c0RbixQ8dHTQ/vnhAV9z6dChQ4cOHTp06NChQ4cOHTp06NDh/4x/ASNRq3/+eJhFAAAAAElFTkSuQmCC" width="35%"> ] No Google Sheets, usamos a função: ``` r =IMPORTFEED("url", "query", "header", "num_items") ``` - A "url" é o endereço do feed rss. - O "query": elemento que queremos extrair. Pode ser "feed", "items", "feed title", "feed url".<br> - O "header" é um valor lógico que indica se a primeira linha contém cabeçalhos.<br> - O "num_items" é o número de itens. [Documentação](https://support.google.com/docs/answer/3093337?hl=pt-br) --- # Extraindo com Google Sheets Extraiam o feed RSS do site da ESPM. Fica aqui: ``` r https://www.espm.br/feed/ ``` Não precisamos de nenhum atributo. Podemos usar aplicativos como o Feedly para encontrar feeds RSS de sites que nos interessam e organizar os feeds em categorias. --- class: inverse, middle, center