class: center, middle, title-slide .title[ # Aula 5 - Obtendo Dados <br> Buscadores ] .subtitle[ ## Jornalismo de Dados ] .author[ ### Leonardo Mancini ] .date[ ### 2025 ] --- # Dados Para desenvolver as reportagens, é necessario obter dados estruturados (também chamados de dados tabulares ou _tidy data_). - Dados estruturados são aqueles que estão organizados em tabelas, com linhas e colunas. - Cada linha representa uma observação e cada coluna representa uma variável. --- class: inverse # Dados estruturados .center[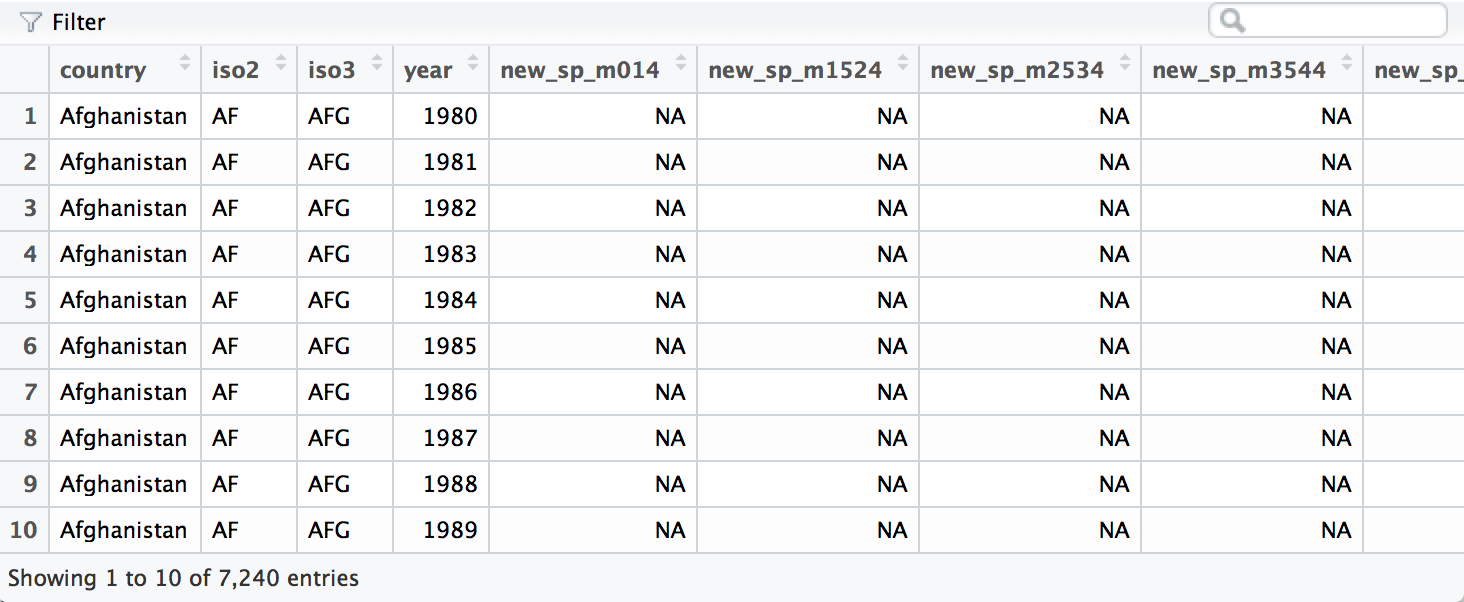] --- # Fontes de dados 1. Organizações da sociedade civil, institutos de pesquisa, órgãos públicos, empresas privadas, etc. 1. Bases abertas em sites de internet. 1. Se não, estruture a sua... --- class: inverse # Caçando dados com buscadores Buscadores como o Google são a forma mais simples de se encontrar um documento _online_. .center[ 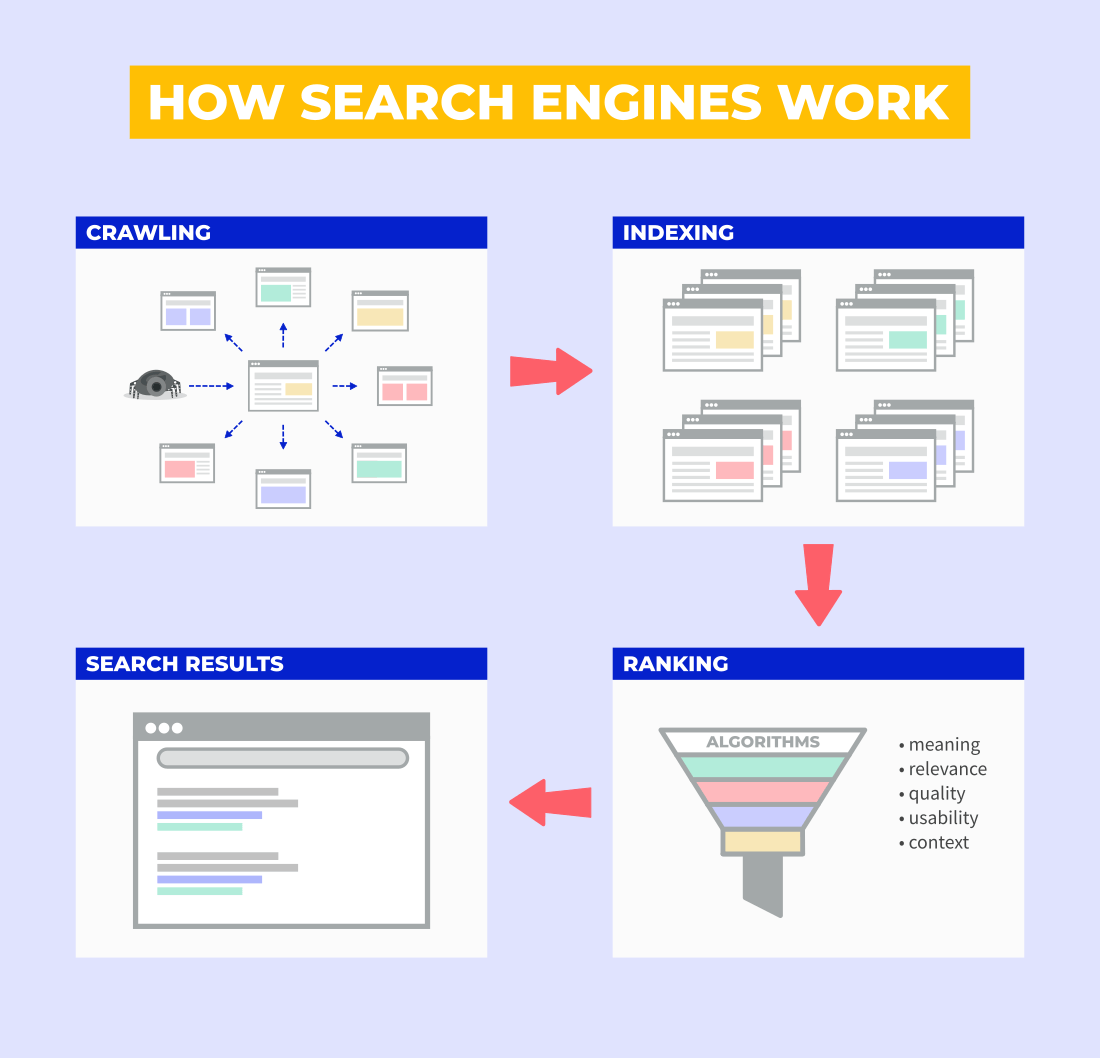] .footnote[Fonte: https://mangools.com/blog/crawling-indexing/] ??? Search Engine Indexes: A search engine index is a database of keywords and website correlations so that search engines can display web pages that match a user's search query. For example, if a user searches for cheetah running speed, the software crawler will look for those terms in the search engine's index. Web crawlers: Search Engine Spider (also known as crawler, Robot, SearchBot or simply Bot) is a program that most search engines use to find new information on the Internet. Google's crawler is called GoogleBot. The program starts on a web page and tracks every hyperlink on each page. Therefore, it can be said that everything on the web will eventually be found and analyzed, because the so-called "spider" crawls from one site to another. When a web crawler visits one of your pages, it loads that page's content into its database. Once a page has been fetched, your page text is loaded into the search engine's index, which is a huge database of words and where they appear on different web pages. robots.txt file: Web crawlers crawl some websites without approval. As a result, every web page includes a robots.txt file that contains instructions to the spider (web crawler) about which parts of the site to index and which to ignore. PageRank algorithm As the web crawler crawls each site, it follows all the links on the site and checks the number of links connected to each site. And then it assigns a percentage to each site that represents the importance of the site using the page ranking algorithm. For example, if there are three sites named A, B, and C. Suppose the number of links connecting to B is from five sites with less percentage and site C with links from A with percentages. Page Rank in a URL graph is a probability distribution used to represent the probability that a random person clicking on links will arrive at a particular page. So there are basically three steps involved in the web crawling process. First, search crawlers start by crawling the pages of your site. It then continues to index the words and content of the website, and eventually it hits the links (website address or URL) on your website. The importance of "robots.txt" The first thing a spider has to do when it lands on your site is look for a file named "robots.txt". This file contains instructions for crawlers about which parts of the site should be indexed and which should be ignored. The only way to control what a spider sees on your site is to use the robots.txt file. All crawlers are subject to certain rules, and most of the major search engines follow these rules. Fortunately, the major search engines like Google or Bing have finally worked together on standards. How many times does the page contain this keyword? Do words appear in the title, in the URL, adjacent? Does the page contain synonyms for these words? Is this page a quality or poor quality site? And then it fetches hundreds of web pages and ranks the importance of those sites using the PageRank algorithm to see how many external links point to it and how important those are? Finally, it combines all of these factors to generate an overall score for each page and returns search results about half a second after the search is submitted. --- # Buscadores _**Web Crawlers (spiders ou rastreadores)**_: são programas que os mecanismos de busca usam para encontrar novas informações na Internet. O rastreador do Google é chamado de GoogleBot. O programa começa em uma página da web e rastreia todos os hiperlinks em cada página. _**Indexadores**_: é um banco de dados de palavras-chave e correlações de sites. _**Page Ranking**_: é um índice que indica a probabilidade de uma pessoa aleatória clicar em um link. _**Robots.txt**_: Os _crawlers_ rastreiam alguns sites sem aprovação. Como resultado, cada página da web inclui um arquivo robots.txt que contém instruções sobre quais partes do site indexar e quais ignorar. --- # robots.txt .center[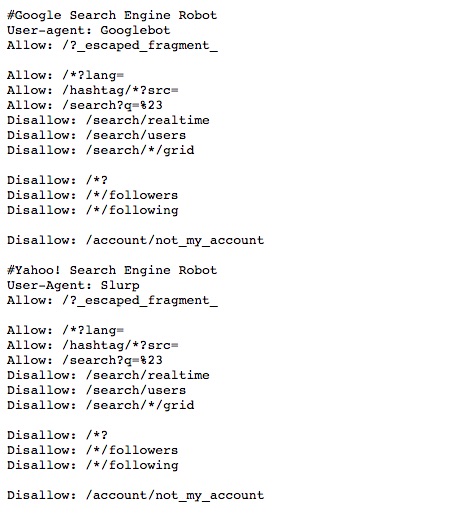] .footnote[Fonte: [A Guide to Robots.txt](https://www.lumar.io/learn/seo/crawlability/robots-txt/)] --- # Query - Para encontrar dados, você utiliza uma _query_ (consulta, interrogação) no campo do buscador. O que o buscador faz é transformar a interrogação em uma fórmula de busca. - A interrogação pode usar linguagem natural ou operadores booleanos. - Operadores booleanos são expressões que aliam regras lógicas a palavras-chave para refinar a busca. --- # Operadores booleanos - **AND**: exige que ambas as expressões estejam presentes na resposta. No <br> Exemplos: "covid AND vacina" ou "covid AND vacina AND Brasil". - **OR**: ao menos uma das expressões tem que estar no documento.<br> Exemplos: "covid OR vacina" ou "covid OR vacina OR Brasil". - **NOT**: exclui a segunda expressão da resposta. No caso do Google, NOT é substituído por "-". <br> Exemplos: "covid NOT vacina" ou "covid NOT vacina NOT Brasil". É possível combinar os operadores booleanos para refinar a busca. Exemplo: "covid AND vacina OR Brasil NOT Fiocruz". --- # Sinais de pontuação Além das palavras-chave e dos operadores booleanos, é possível utilizar sinais de pontuação para refinar a busca. <small> .pull-left[ - **""** (aspas): busca por uma expressão exata. <br> Exemplo: "Vacinação contra Covid". - **-** (hífen): exclui palavras-chave da busca. <br> Exemplo: "Vacinação contra Covid -Fiocruz". - **..** (dois pontos): busca por um intervalo de números. <br> Exemplo: "Vacinação contra Covid 2020..2021". ] .pull-right[ - **()** (parênteses): agrupa palavras-chave. <br> Exemplo: "Vacinação contra (Covid OR H1N1)". - ** | ** (pipe): busca por palavras-chave alternativas. <br> Exemplo: "Vacinação contra Covid | H1N1". - ** * ** (asterisco): busca por palavras-chave com variações. <br> Exemplo: "Vacinação contra * Brasil". ] --- # Operadores de busca Em alguns buscadores, há a possibilidade de se adicionar operadores de busca para refinar a pesquisa. <small> .pull-left[ - **site**: limita a busca a um site específico. <br> Exemplo: "site:fiocruz.br covid". - **filetype**: limita a busca a um tipo de arquivo específico. <br> Exemplo: "filetype:pdf covid". - **intitle** ou **allintitle**: limita a busca ao título da página. <br> Exemplo: "intitle:covid" ou "allintitle: covid vacina". ] .pull-right[ - **inurl** ou **allinurl**: limita a busca à URL da página. <br> Exemplo: "allinurl:covid vacina". - **intext** ou **allintext**: limita a busca ao texto da página. <br> Exemplo: "allintext:covid vacina". - **before** ou **after**: limita a busca a um intervalo de tempo. <br> Exemplo: "covid before:2021" ou "covid after:2020". - **cache**: exibe a versão em cache de uma página. <br> Exemplo: "cache:fiocruz.br". ] </small> .footnote[ Fonte: [Google Search Operators](https://ahrefs.com/blog/google-advanced-search-operators/)] --- #Google Dorks ou Google Hacking São buscas avançadas no Google que permitem encontrar informações sensíveis em sites. Arquivos confidenciais em sites: - filetype:pdf intitle:confidencial site:gov.br Diretórios de arquivos: - intext:"Index of /" site:fiocruz.br Base de dados de sites: - site:gov.br intitle:"index of" *.csv - site:gov.* intitle:"index of" *.csv .footnote[ Fonte: <br> 1 - [Google Hacking Database](https://www.exploit-db.com/google-hacking-database)<br> 2 - [So you think you can Google? - Workshop GIJN](https://gijn.org/resource/tips-for-optimizing-google-search-in-investigations-from-online-expert-henk-van-ess/) ] ??? Google dorks: https://github.com/BullsEye0/google_dork_list/blob/master/google_Dorks.txt https://github.com/arimogi/Google-Dorks https://github.com/cipher387/Dorks-collections-list?tab=readme-ov-file#googledorks https://www.boxpiper.com/posts/google-dork-list https://ahrefs.com/blog/google-advanced-search-operators/ --- class: inverse # Exercício Encontre informações sobre o seu tema usando os operadores booleanos e de busca. Adicione à pauta que estamos elaborando para o trabalho final.